CFR: Crossmodal Feature Replacer at ICML 2026
Written on July 3rd , 2026 by Yuan Guo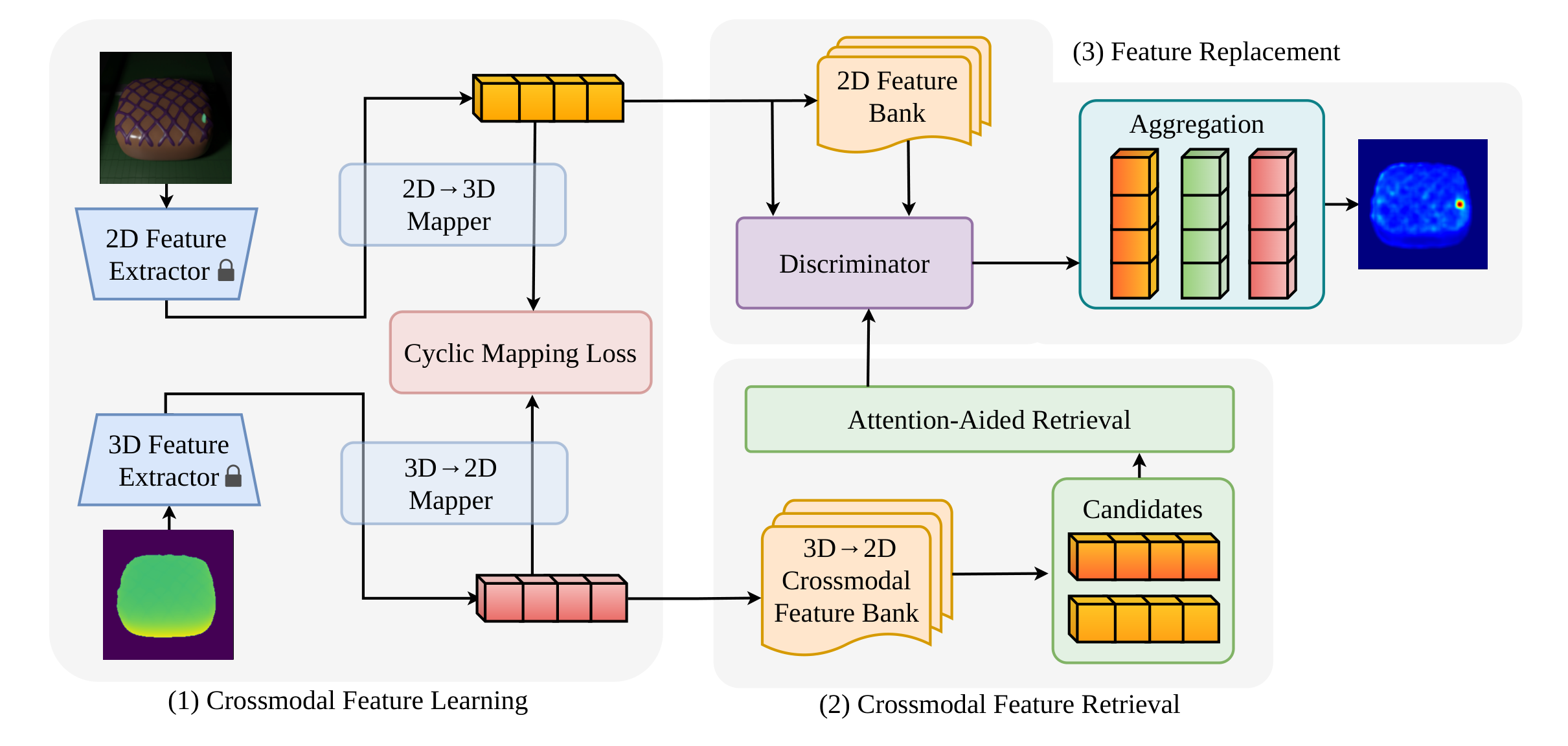
I am happy to share that my paper, “Remove the Ambiguity: Few-shot Multimodal Anomaly Detection Using Crossmodal Feature Replacer,” has been accepted to ICML 2026.
Code is available at github.com/Yuan-Honoka-Guo/CFR.
This project is about a simple but stubborn question in industrial anomaly detection: if we only have a few normal samples, how can a model learn what defects look like without ever seeing defects during training?
The usual answer is to make the model learn normality so tightly that it fails on anything outside that distribution. In RGB–3D anomaly detection, that means using both appearance and geometry. RGB images know about color, texture, illumination, and surface appearance. Point clouds know about shape and depth. If the two modalities disagree, something interesting may be happening.
But the disagreement is not always a defect. That is where CFR starts.
The Loss Curve That Started It
CFR was not born from a clean theory first. It started from a strange reconstruction-loss pattern.
I began from a crossmodal feature mapping baseline: predict the feature descriptor of one modality from the descriptor at the corresponding position in the other modality. If the predicted feature does not match the observed feature, the point is treated as suspicious. This has an intuitive “garbage in, garbage out” flavor: normal correspondences should be learned, while anomalous patches should be mapped somewhere inconsistent.
The first idea was to make the mapping route more constrained. A pair of single-direction networks can overfit to accidental routes between feature manifolds, so I added cyclic reconstruction loss: 2D maps to 3D and then back to 2D, while 3D maps to 2D and then back to 3D. This encouraged a more bijective correspondence and gave a direct improvement in segmentation accuracy.
But the loss curves kept showing an asymmetry. Across the experimental settings I tried, the 3D-to-2D reconstruction loss was consistently worse than the 2D-to-3D direction. Making that branch deeper did not solve it.
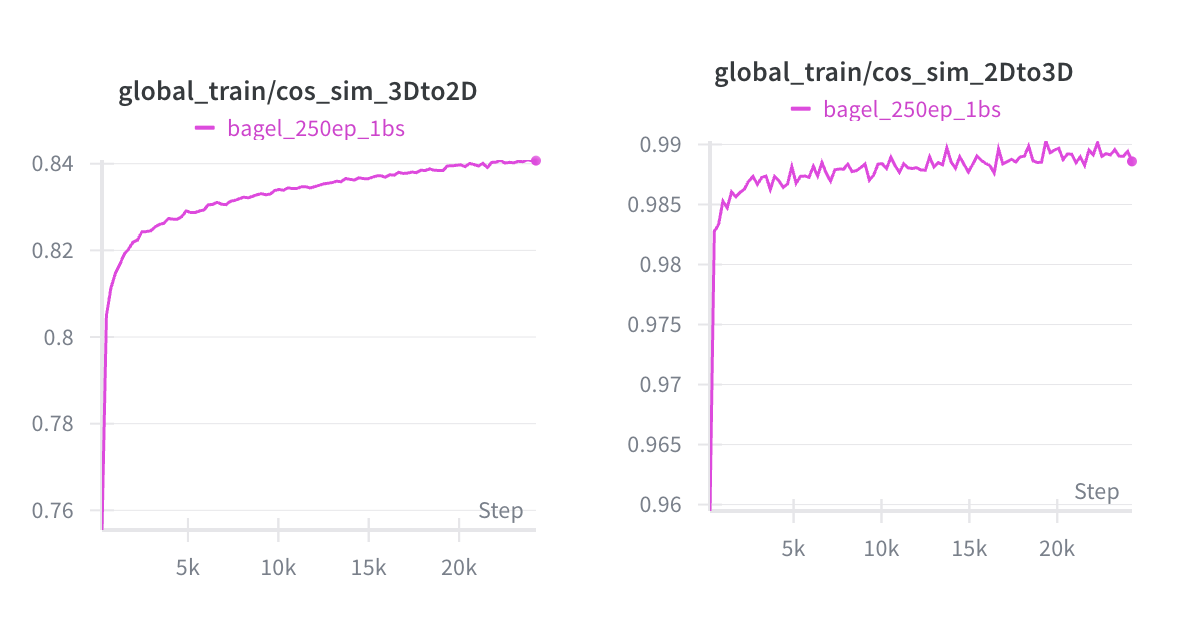
My first guess was that the 3D features were simply weaker. Maybe PointNet-style features were too scattered or too simple compared with ImageNet features, so the model did not have enough information to recover RGB features. To test that, I converted the point cloud into surface normals and used DINO for both sides, so both modalities were represented through the same visual backbone.
The result was revealing: the 3D-to-2D loss became a little better, but it still did not match the 2D-to-3D direction, and the test-time accuracy dropped. That pushed the explanation away from “the 3D backbone is weak” and toward a more structural issue.
The problem was ambiguity. A local 3D shape can correspond to many valid RGB appearances. Two normal objects can share nearly identical geometry while having different colors, lighting, gloss, or texture. During training, the network is asked to reduce loss for all of those valid targets. A deterministic mapper then learns an averaged output, similar to a collapsed autoencoder. The averaged feature is not a real normal appearance, and that hurts exactly the sensitivity anomaly detection needs.
That observation became the main inspiration for CFR: instead of forcing a single reconstruction network to answer every ambiguous 3D-to-2D query, detect when the reconstruction is unreliable and replace it with a plausible normal feature retrieved from memory.
The One-to-Many Problem
A common reconstruction-based strategy is to map features from one modality to the other. Given a 3D feature, reconstruct its RGB feature. Given an RGB feature, reconstruct its 3D feature. If the reconstruction error is high, mark it as anomalous.
This is elegant, but it hides a hard assumption: that the mapping between modalities is close to one-to-one.
In real objects, this is often false. Two items can have nearly the same 3D geometry while having very different RGB appearances. A candy can keep the same layered shape while changing colors. A surface can keep the same depth structure while changing gloss or texture. In those cases, a single 3D feature may correspond to multiple valid RGB features.
When a deterministic reconstruction network is forced to learn that one-to-many mapping, it tends to average the valid answers. The result is not a faithful RGB feature. It is a collapsed, over-smoothed compromise that matches none of the real possibilities. Then normal regions can produce large reconstruction errors and become false positives.
In other words, the model is not failing because the sample is anomalous. It is failing because the crossmodal question was ambiguous.
The CFR Idea
CFR stands for Crossmodal Feature Replacer. The main idea is to stop asking the reconstruction network to solve every ambiguous correspondence by itself.
Instead, CFR combines two behaviors:
- Learn a coarse crossmodal reconstruction between RGB and 3D features.
- At inference time, identify unreliable reconstructed RGB features and replace them with high-confidence normal features retrieved from memory.
This makes the pipeline coarse-to-fine. The reconstruction network gives an initial prediction. The memory bank acts as a source of plausible normal candidates. The replacer decides when the reconstruction looks unreliable and swaps in a better feature.
That replacement step is the key difference. CFR does not merely ask, “Can I reconstruct this feature?” It also asks, “Is this reconstructed feature a trustworthy member of the normal feature distribution?”
Framework
Figure 2 from the camera-ready paper shows the full CFR model.
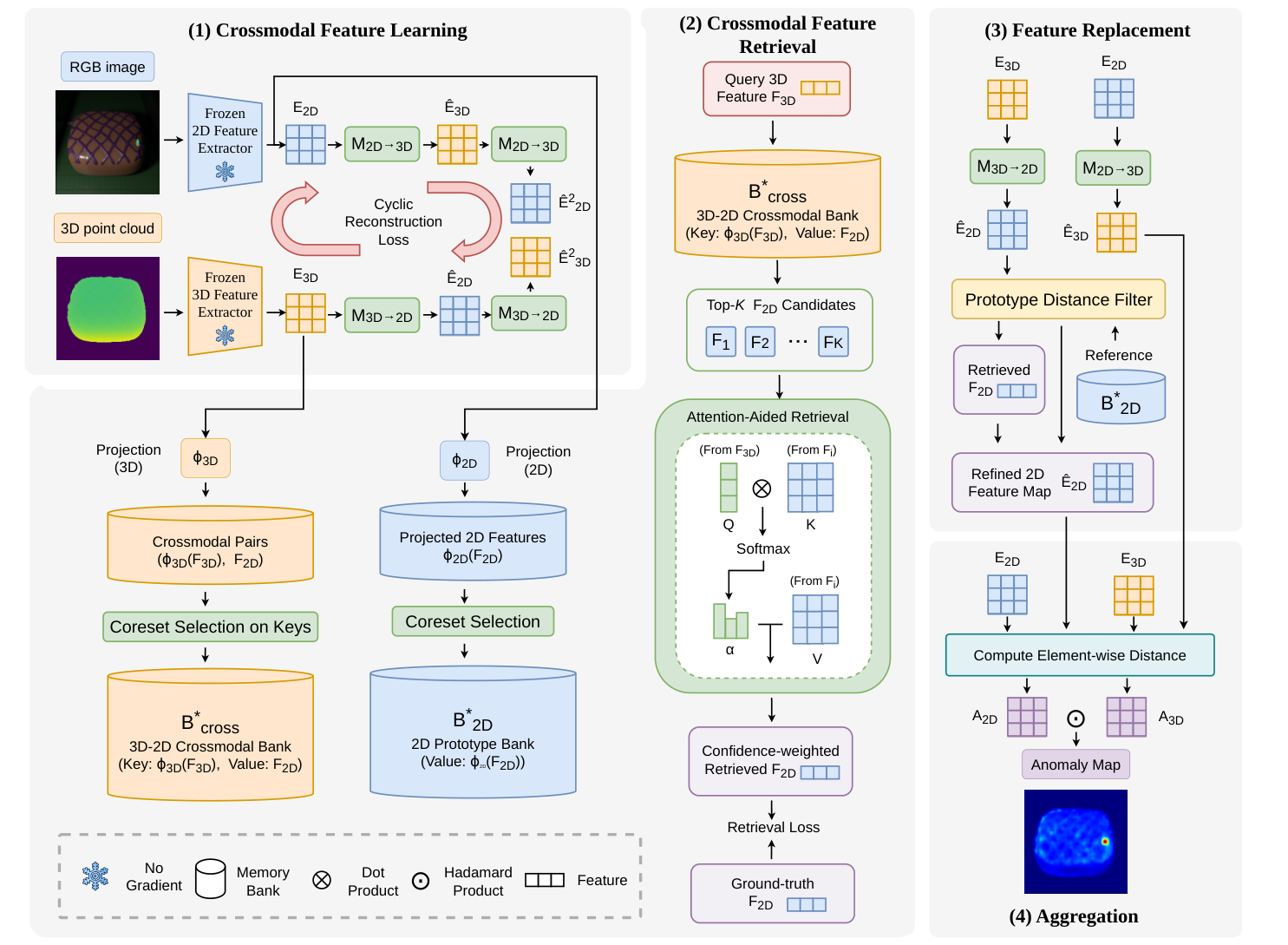
CFR begins by extracting aligned RGB and 3D features. In the experiments, RGB features come from a frozen DINO ViT-B/8 backbone, while 3D point cloud features come from Point-MAE. Because the datasets provide pixel-aligned RGB and 3D coordinates, each 2D feature can be paired with a corresponding 3D feature.
Then CFR trains two crossmodal mapping functions:
\[M_{2D\to3D}\]and
\[M_{3D\to2D}.\]These mappings are trained cyclically. A 2D feature can be mapped to 3D and then back to 2D. A 3D feature can be mapped to 2D and then back to 3D. This cycle-consistency constraint encourages the learned translation to preserve the physical correspondence between modalities instead of drifting into arbitrary feature space.
At the same time, CFR builds memory banks from normal training features. One bank stores 2D normal prototypes. Another works as a crossmodal key-value bank: projected 3D features are used as retrieval keys, and paired 2D features are used as values. To keep this practical, features are compressed with random projection and pruned with coreset selection.
During inference, CFR first reconstructs the feature maps. Since the one-to-many ambiguity is mainly observed in the 3D-to-2D direction, CFR applies filtering and replacement to reconstructed 2D features. If a reconstructed feature lies far from reliable normal prototypes in the 2D bank, it is marked as unreliable.
For those unreliable features, CFR retrieves top candidates from the crossmodal memory bank. Instead of using a brittle nearest-neighbor hard assignment, it applies lightweight attention over the top-K candidates and produces a confidence-weighted replacement feature.
Finally, CFR compares original and reconstructed feature maps in both modalities, aggregates the 2D and 3D anomaly maps, and smooths the final anomaly scores.
Results
We evaluate CFR on MVTec 3D-AD and Eyecandies, two RGB–3D anomaly detection benchmarks. The setting is few-shot and normal-only: for each class, the model trains with only 1, 2, or 4 normal samples.
On MVTec 3D-AD, CFR achieves the best mean performance across the few-shot settings in our experiments:
| Setting | I-AUROC | 30% AUPRO |
|---|---|---|
| 1-shot | 74.0 | 92.3 |
| 2-shot | 77.1 | 93.1 |
| 4-shot | 80.5 | 94.2 |
On Eyecandies, where appearance variation makes the one-to-many mapping problem especially visible, CFR also performs strongly:
| Setting | I-AUROC | 30% AUPRO |
|---|---|---|
| 1-shot | 75.9 | 82.7 |
| 2-shot | 75.8 | 84.5 |
| 4-shot | 77.9 | 84.7 |
The 1-shot Eyecandies result is especially meaningful to me. CFR reaches 75.9 I-AUROC and 82.7 AUPRO at 30% FPR, outperforming the second-best method by 11.8 and 2.8 points. On Chocolate Praline and Licorice Sandwich, two classes where similar geometry can hide very different appearances, CFR improves I-AUROC by 13.6 and 25.5 points, and AUPRO by 6.2 and 8.4 points.
Those gains support the original hypothesis: when geometry is similar but appearance varies, replacing ambiguous reconstructions can recover discriminative information that plain reconstruction loses.
What the Ablations Say
The retrieval and replacement module is not just decorative. In categories with strong one-to-many behavior, adding attention-aided retrieval improves mean I-AUROC by 6.2 points and 30% AUPRO by 2.8 points over the version without retrieval.
The cyclic reconstruction loss also matters. Even without the replacement module, cyclic feature mapping improves over a plain prediction-based baseline, which suggests that encouraging cycle-consistent correspondence between RGB and 3D features is useful on its own.
There is also an interesting failure mode hiding in the experiments: sometimes adding more training shots can hurt image-level detection. For categories like Hazelnut Truffle, extra normal samples add more valid RGB appearances for nearly the same geometry. That can intensify the one-to-many mapping ambiguity. More data is usually good, but for deterministic crossmodal reconstruction, more normal variation can also make the mapping less decisive.
This is a useful warning for future multimodal anomaly detection methods. The problem is not only data scarcity. It is also modality imbalance and crossmodal ambiguity.
Takeaway
CFR is built around a small shift in perspective. Reconstruction is useful because it encourages generalization failure on anomalies. Memory banks are useful because they preserve concrete normal examples. But each has a weakness: reconstruction can collapse ambiguous mappings, and retrieval can be brittle when it commits to a single neighbor.
CFR tries to make them cooperate. Reconstruction gives a first guess. Retrieval supplies plausible alternatives. Feature replacement corrects the places where the first guess is not trustworthy.
For me, the most exciting part of this work is that the central problem is not just “how to improve anomaly detection numbers.” It is more specific and more interesting: how do we design multimodal systems that respect ambiguity instead of pretending it is not there?
That question, I think, will keep showing up wherever vision systems try to connect different views of the same physical world.
